
Scientific research is generating far more data than the average researcher can get through. Meanwhile, modern computing has yet to catch up with the superior discernment of the human eye. The solution? Enlist the help of citizen scientists. British astronomer and web developer Robert Simpson is part of the online platform Zooniverse, which lets more than one million volunteers from around the world lend a hand to a variety of projects — everything from mapping the Milky Way to hunting for exoplanets to counting elephants to identifying cancer cells — accelerating important research and making their own incredible discoveries along the way.
At TED2014, Simpson took us through a few of Zooniverse’s 20-plus projects (with more on the way), some of which have led to startling discoveries — including a planet with four suns. Below, an edited transcript of our conversation.
Are you a scientist?
Well, I’m a distracted astronomer. Yes, I’m an astronomer at University of Oxford. But I’m there to create crowdsourcing projects where we put data — usually images, but sometimes videos or sound — online, and ask the public to do research tasks that we used to ask postgrads to do. This helps us go through lots and lots and lots of data very quickly — which means scientists are free to concentrate on the hard, analytical parts of the problem.
So you’re giving volunteers the grunt work, basically?
Yeah, but what’s weird is that people love it. And not only do they enjoy it, and engage with each other online, they make discoveries, too. That’s what’s so special about it. We don’t just get the scientists’ science done. We open up the possibility for everyone to start participating in creating their own science projects using data.
We have really sophisticated computers. What can the human eye detect that a machine can’t?
A lot. I mean, a lot. With Zooniverse’s original project, Galaxy Zoo — which asked volunteers to discern between spiral galaxies versus elliptical galaxies — that was something that computers really couldn’t do at the time. Actually, they still really can’t do it unless we use the human data that we’ve gathered to train them. The computer can get it right maybe 85 percent of the time. But the 15 percent where it fails are the most interesting objects. So the reason it fails is they’re weird, funny shapes or funny colors. There’s something about them that’s slightly abnormal. These are the objects people can identify that the computer can’t — and those are precisely the ones that are scientifically interesting. So by definition, the computer isn’t doing the bit we want it to do.

Examples of the different types of galaxies Zooniverse volunteers help categorize. Image: GalaxyZoo.org
Having said that, we’ve been able to train the computer to do a much better job based on the human answer, which is great news. But still, we want to ask for more — we want to cover weird, harder galaxies. So that project will just keep going, because people will always be looking at the harder set.
In another example, our project Planet Hunters has people looking through light curve data from stars, gathered using Kepler. So we stare at 150,000 stars, and watch the light from them. The whole point of doing this is to occasionally catch a planet passing in front of the star, and see a dip in light as it goes past. That dip can tell you how big the planet is, how often the planet’s going around the star, all sorts of stuff. You’ve just got to stare for long enough, and you’ve got to do it with a really, really, really good instrument.
Now, NASA and the Kepler team have used computer algorithms to look through this data for years, and they find lots of planets. But based on our experience with galaxies, we thought there must be stuff in this data that people will see that the computer can’t, because a computer is trained to look for certain things. It’s programmed by a person. Sure enough, we found planets that they didn’t find. And we found ones that are in weird, amazing configurations — some of which don’t make any physical sense — but they exist. For example, we found a planet in a seven-planet system around a sun-like star. That was an amazing discovery, because the more planets you have, the more crazy and chaotic all these dips get as they go back and forth.
Do you give each volunteer one star to look at?
No, it’s a bit like the galaxies. There will be something like 10 or 15 people who look at each one. But we can email them and say, “You found a planet!” — which is quite a fun email to send. A lot of those people have become authors on papers, because we can’t offer the naming rights. But we can say, “You’re a planet discoverer, and without you, we wouldn’t know this planet exists.”
What’s the most extraordinary thing your volunteers have found?
With one of the first planets we found, there were two stars in the middle, orbiting around each other — and orbiting those was a planet. And then outside of all of that are two more stars that orbit each other, and orbit the entire thing, twisting around. So this planet has four suns — two of which go up and down together in the night sky, and are very bright. The other two are a bit fainter, and go around together on the outside. It’s an amazing idea, but it’s exactly the sort of system that a computer can’t find.
We also found a planet with two suns, like Tatooine. The Kepler team announced it, then we looked, and realized we had it too, we just hadn’t gotten there quick enough with the press release. So we’ve found weird and wonderful stuff.
When the human-generated data comes back, is there someone at Zooniverse that is responsible for analyzing it?
We rely on statistics to group and sort the crowd’s work. It used to be that we simply got everything looked at about 50 times, and the average or median answer was all we wanted. But now we’re a bit cleverer about it.
For example, Snapshot Serengeti is a biodiversity project about the interaction of species within Serengeti National Park. The researchers want to study the populations of lions, hyenas, cheetahs and leopards, so they placed 200 cameras in the park. Now, they knew this was a lot, but they never realized they’d end up with quite as much data as they did. The motion-triggered cameras go off because the sun comes up at a certain angle, hot-air balloons with tourists go past, the grass waves. They’re simply overwhelmed by the number of images generated. They have something like 1.7 million to go through — and two researchers. They can’t even try and do it on their own.

Examples of images from the Snapshot Serengeti project. Image: Zooniverse
I think 60 percent of the data turned out to be waving grass. So we said, “Okay, well, if three out of five people see an image and say it’s grass, we’ll just remove that one from the system.” Then you end up with more and more animals to see as the grass photos get deleted. But after that, everything’s just statistical. Each image is viewed something like 20 times. From there, we structure the database. All right: here’s all the giraffes.
I actually have a poster in my office which is a big photo mosaic of a wildebeest — known as the “cheetah burgers” of the Serengeti, because they’re just eaten constantly by the cheetahs — made up of images of wildebeests, all identified by Zooniverse volunteers. We did the same with zebra, lions and elephants as well, just for fun. We’d suddenly realized we could just click a button and get 17,000 pictures of elephants.
What sorts of unusual things do human eyes detect on the Serengeti project?
In Snapshot Serengeti, we don’t ask people to tell us about the birds, because the researchers who are working on it don’t really care about them. So we just have a button called “bird.” There are a bunch of volunteers on the project who have said, well, we happen to know about birds. So they’ve been systematically tagging all the bird pictures, and because of their enthusiasm and participation, we’ve catalogued all the birds as well, for free.
And the bird data could be valuable to someone someday.
Exactly. They are really just adding another group of species to our list.
A good category is fire, actually. You get fire in the Serengeti a lot, and so people have been hashtagging fire as well. Humans is a fun one too, because there are humans in the pictures. There are the rangers who set the cameras up, do test shots with a clapperboard. The only time we’ve ever had to remove any data from a project was because some tourists set up camp, unwittingly, next to one of the cameras. Nothing too rude, but it was, you know, not dignified.
You should warn people.
We thought that no one would ever camp there. It’s in the middle of the Serengeti. It’s probably dangerous.
In the cancer research project Cell Slider, you mentioned that people are looking for patterns. What are these patterns made of?
Cell Slider takes data from anonymized medical research trials that were run out of Cambridge, UK, and they’ve been dyed certain colors. We ask people to look at the exact same images the researchers look at if they want to identify cancerous cells and tumors, or even size abnormalities in the tissue. We give examples to guide them, and there’s a brief tutorial. It’s just pattern recognition, but this one of those tasks that PhD students would have spent half their week doing. Now they have their whole week back, which is really is speeding up their work.
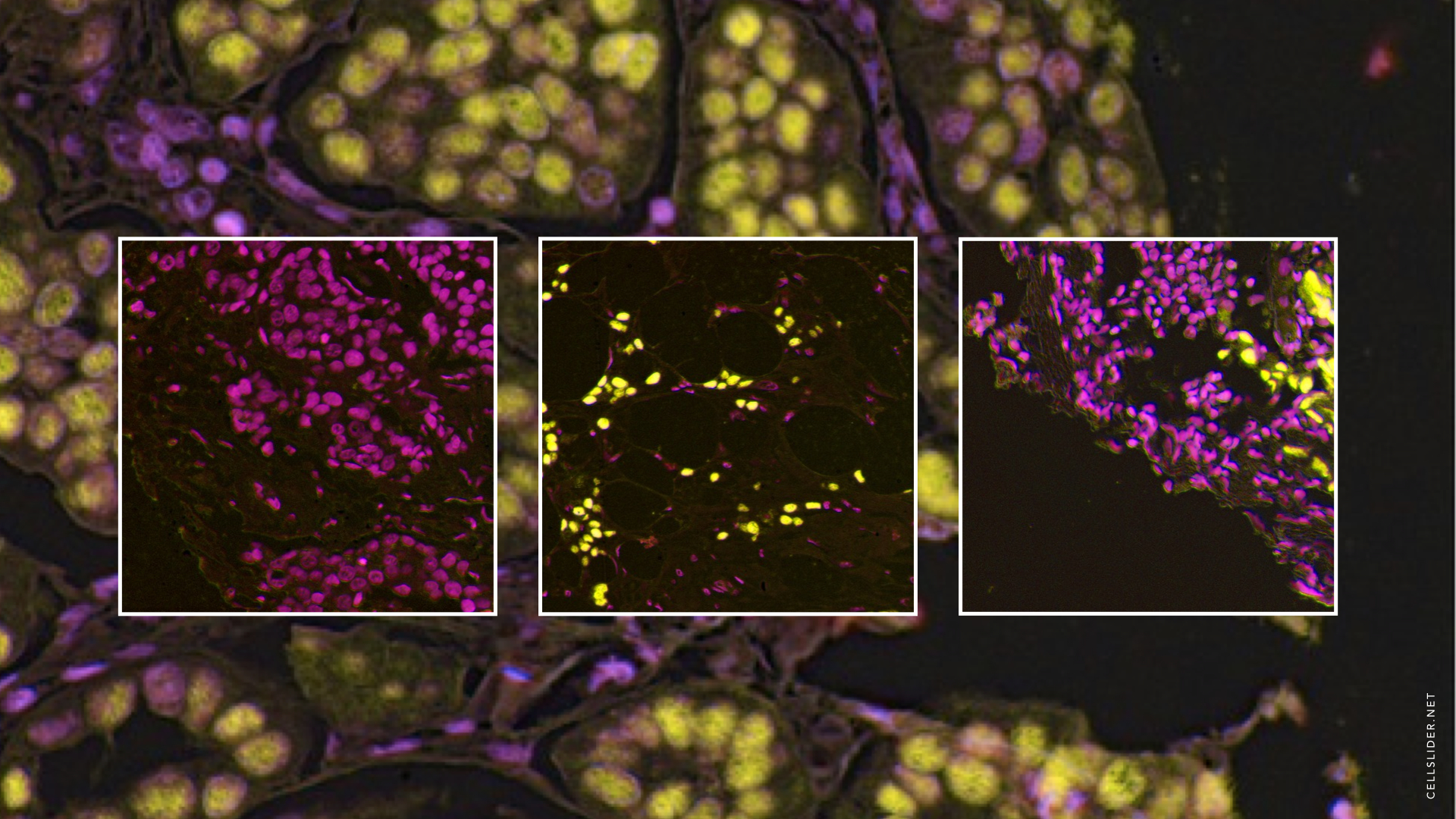
Examples of data to be classified on CellSlider.net. Image: Zooniverse.com
We have another medical project, called Worm Watch Lab. We watch nematode worms that lay eggs in petri dishes. A computer can do a lot of clever recognition around these worms, but it cannot tell you when it lays the eggs. And so we show volunteers video clips of the worms, and they have to hit the “Z” key — like a game almost — when they see an egg being laid. I think it’s absolutely disgusting, and it creeps me out to even watch them. They’re so horrible, these tiny, horrible microscopic worms — but this is again cancer research. The worms have been given various genetic mutations, and one of the phenotypes for the genetic mutation that seems to correlate with cancer has to do with egg-laying capabilities.
You’ve learned a lot about lots of different kinds of science that you wouldn’t otherwise have been exposed to.
Yes, and this is the amazing thing — once we stepped out of astronomy, all these people come to us with all these amazing scientific stories, and we can help them speed it up. And I get to be published in journals that are nowhere near my expertise, which is quite fun as well.
One of the appealing aspects of Zooniverse is its social platform. How is community-based discussion built in?
There’s a discussion platform alongside all of our projects called Talk. Once volunteers are finished “classifying” an object, we ask, “Do you want to discuss this object?” You leap onto the discussion platform, we see the same picture, and you can make a comment on it. So you might say “Ah, this is very nice.” Or you might say, “Is this a spiral galaxy?” Maybe you’re not sure. Or “Is that an elephant in the corner?” Or “Hey, this is really interesting: there’s three birds on this elephant’s back. Why is that?”
The same platform is used by everyone in the system, so the scientists see the same thing, and can answer people’s questions. You’ll also see everything anyone’s ever said about the picture. So you can land on something strange and it turns out 25 other people also noticed it, and you can begin a conversation about it. It’s through this process that unusual things have been discovered.
How do you monitor the community forum? Aren’t the scientists too busy with research to watch the boards?
We allow volunteers to say if they’d like to be a moderator, so at the beginning of each project, a couple of scientists will choose moderators. After that, it starts to take care of itself. The scientists are generally in there answering questions when possible, if they are not too overwhelmed. But often, there are whole groups of scientists eager to help people.
This means that the scientists get to know a lot of the more of the dedicated users, the people who come back again and again. And they can ask them for specific help, say, “Hey, I’ve got this project where I’m looking for worms at the bottom of the ocean. If you see any, can you hashtag it with ‘worms?’” So there’s a second layer of science that can go on, based on relationships made on the platform.
There’ll always be a group of enthusiastic people to help. And the nice thing is, we’ve had people go from playing about on the web to getting so involved that they are published as scientists in papers. Hundreds of dedicated Zooniverse volunteers have had their names listed as author on academic papers because they gave so much of their time and got to know the scientists.
Can anyone at all join in? Do children participate, for example?
Yes. I know for a fact that one of the people who obsessively categorized nearly a million galaxies was about 13 at the time, a home-schooled girl in the UK. She came and did work experience with us a couple of years ago and is awesome. All this stuff happened because she just got to know us. Anyone can participate: the sign-up requires an email address and a username, just to track people who are taking part, for user-weighting our statistical work, and so on.
It sounds like people are devoting an incredible amount of time to Zooniverse projects. In your talk, you contrasted time spent volunteering on Zooniverse to playing Angry Birds. But as Jane McGonigal famously points out, games alleviate stress, pain and so on. Do you think there’s something similar inherent in your system? What’s the reward?
Early on, we wondered the same thing: why does anyone give so much time? We’ve been doing this since 2007. In the first project, there were more than 900,000 galaxies that needed to be categorized. About 160,000 people took part in that, and of those, around 10 people categorized every single galaxy. That would have taken them months of effort, assuming they were working on it every day. But they did. We wondered why these people would make such an extraordinary effort.
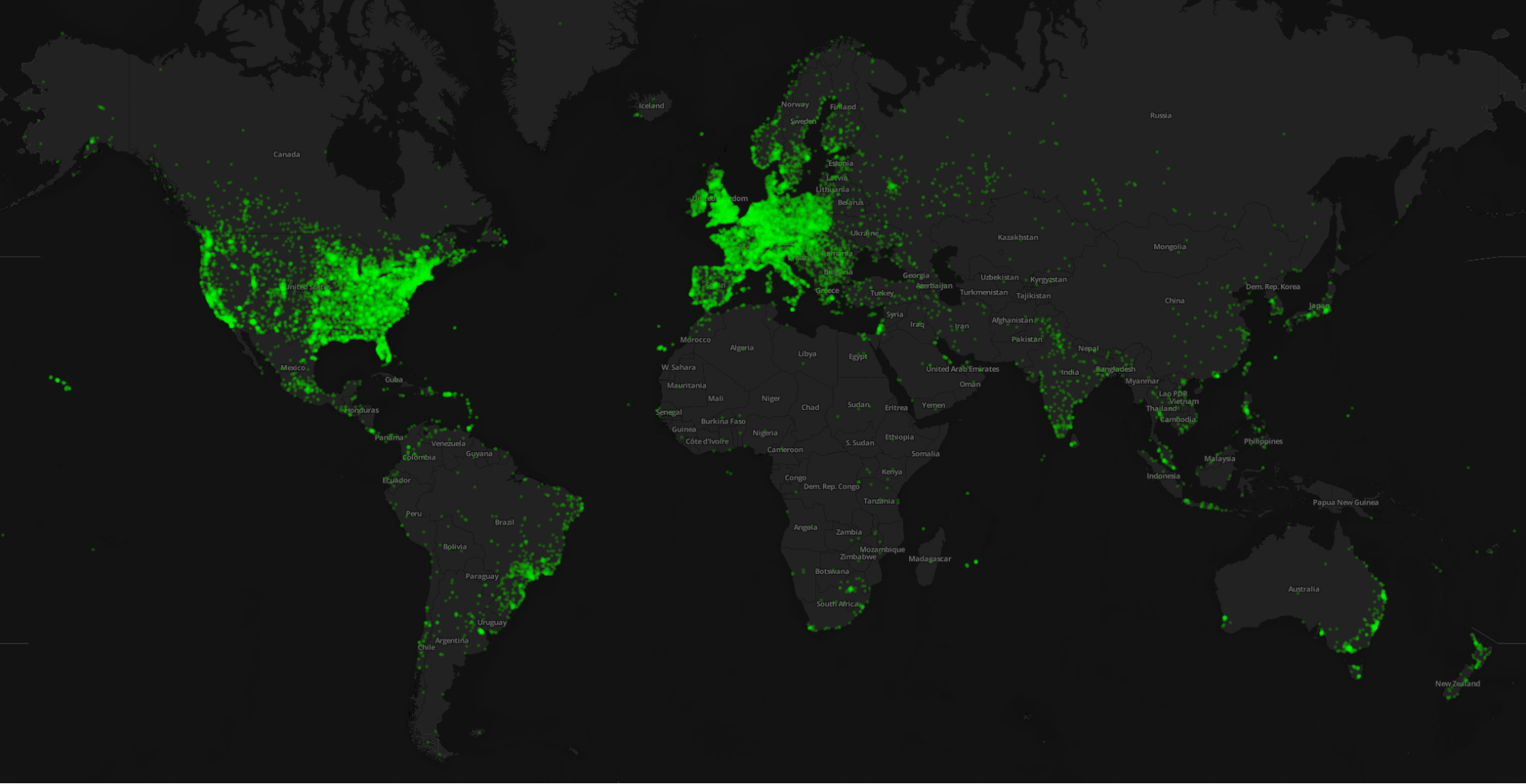
Zooniverse’s one million volunteers across the planet. Image: Zooniverse.com
So we surveyed a lot of users. We gave them lots and lots of options. They could have said, “I like astronomy,” “I like to think about the universe,” “I like playing games.” All of these answers were available. But the one motivation common to nearly half the people involved was that they want to contribute to science. They want to be useful. We’ve taken that to heart and work very hard to ensure that the Zooniverse is always trying to be more efficient, and that every click helps.
Comments (14)
Pingback: Mazda names four TED Fellows “Rebels with a Cause.” Psst: One of their new projects will get funded based on your vote | TEDFellows Blog
Pingback: Julie Freeman launches new online artwork, We Need Us | TEDFellows Blog
Pingback: Research data, citation and software repositories for the savvy astronomer. | chasing telescopes
Pingback: “We Need Us”: Julie Freeman shows new work at the Tate Modern Turbine Hall | TEDFellows Blog
Pingback: What a Zooniverse to behold! | Spotlight on Good
Pingback: Zooniverse: Real Science Online | OPEN MINDS LEARNING
Pingback: You found a planet!: Robert Simpson crowdsources scientific research | TEDFellows Blog